

QU.IT une plateforme électronique d’aide au travail des traducteurs littéraires
Table
1. Un corpus comparable monolingue
2. Un corpus parallèle de traduction (bilingue et plurilingue)
3. Une base de données lexicographiques
4. Une mémoire de traduction et un outil d’analyse contrastive
5. Exemple de consultation de QU.IT : le québécisme de statut « face »
6. Exemple de consultation de QU.IT : le québécisme léxématique « niaiseux »
Résumé
Dans cette brève contribution, nous nous concentrons essentiellement sur le fonctionnement et la démarche de consultation de la plateforme QU.IT, une ressource électronique qui intègre à la fois un corpus comparable monolingue, un corpus parallèle bilingue, une base de données lexicographiques et une mémoire de traductions commentées. Ce projet, limité à la description des variantes topolectales du français au Québec, se veut une expérimentation d’une méthode qui pourrait être appliquée à des projets de plus grande envergure prenant en compte toute la langue française. Par la création de cette plateforme, nous souhaitons éveiller un intérêt pour la création d’outils spécialement conçus pour faciliter le travail d’un traducteur littéraire.
Abstract
This article briefly presents how the platform QU.IT works and how to consult it properly. It is an electronic resource including a monolingual comparable corpus, a bi-/plurilingual parallel corpus, a lexicographical database and a translation memory with comments. This project, which is limited to the description of French Québec topolectal variety, is meant to be an experimentation of a method which could be applied to larger-scale projects taking into account French language as a whole. By creating this platform, we intend to attract attention to the need for specific literary translation tools.
Introduction
Déjà dans les années 80, l’informatique avait envahi en quelques années l’activité de nombreux secteurs professionnels (VAUQUOIS 1981 : 15). Le monde de la traduction professionnelle, en particulier technico-scientifique, en a été évidemment affecté. Initialement, les outils d’aide à la traduction avaient été essentiellement développés par des non-traductologues. Il a fallu attendre les années 90 pour voir s’affirmer la traductique, « issue de l’introduction de l’informatique dans la pratique de la traduction » (GUIDÈRE 2010 : 115), qui a contribué au développement d’outils destinés aux traducteurs. Ces outils informatiques peuvent en effet simplifier leur métier qui, dans la société de l’information, s’est transformé tant en termes de savoir-faire que de comportements. « Il requiert des aptitudes générales : une aptitude à traduire, une aptitude à la recherche documentaire (et terminologique), et enfin une attitude à travailler vite sous la pression du temps » (LEBTAHI 2004 : 223).
Ces compétences sont attendues aussi de la part d’un traducteur littéraire. Cependant, il n’existe encore à notre connaissance aucun outil conçu spécifiquement pour supporter son travail.1 De fait, au vu des publications scientifiques, on sent une réticence de la part des concepteurs et des traducteurs qui voient la traduction littéraire comme l’apanage de la création artistique, pour laquelle toute intervention non-humaine serait malvenue. À cette réticence s’ajoute la triste réalité du monde de l’édition qui fait en sorte que la traduction littéraire ne soit pas toujours confiée à des spécialistes, et que le décalage avec la traduction littéraire académique soit parfois flagrant.
C’est le cas pour les traductions des ouvrages littéraires québécois dont nous avons analysé un corpus assez large (ZOTTI 2011 : 449-451). Nous avons pu constater qu’il s’agit parfois de traductions d’« amateurs », c’est-à-dire faites par des traducteurs qui semblent ignorer les particularités du français québécois. Dans cette contribution, nous présentons QU.IT, base parallèle de la littérature Québécoise traduite en Italien, dont la plateforme est disponible en ligne depuis 2014 à l’adresse www.quit.unibo.it. Conçue au cours de trois stages de recherche à l’Université Laval au Québec, elle a pour but de fournir aux traducteurs une ressource qui leur permette de surmonter certains problèmes linguistiques de la traduction littéraire, notamment la reconnaissance et la compréhension des variantes topolectales du français en usage au Québec. Nous avons en effet relevé que ces variantes, pas toujours reconnues ou identifiées comme telles, surtout lorsqu’il s’agit de québécismes sémantiques (POIRIER, 1995),2 sont souvent sources d’erreurs d’interprétation et, par la suite, de traductions inacceptables (cf. ZOTTI, 2011, 2014a, 2015).
Nous ne nous arrêterons pas ici en détail sur les caractéristiques de QU.IT. Dans cette brève contribution on ne pourrait pas résumer toute la réflexion à l’origine de sa réalisation et le parcours de son implémentation progressive. Nous renvoyons à nos études où nous avons déjà illustré les critères de constitution et d’interrogation du corpus, ainsi que les fiches d’analyse intralinguistique et contrastive intégrées dans la base (ZOTTI, 2011), le repérage des entrées et des expressions et le corpus parallèle et la mémoire de traductions (2014a), et donné quelques exemples d’analyse portant sur des mots du français parlé québécois marqués sur le plan diastratique et diaphasique (2015). Dans ce volume consacré aux projets numériques dans le domaine des études françaises, il nous semble pertinent de nous concentrer essentiellement sur le fonctionnement et la démarche de consultation de cette plateforme électronique.
La démarche que QU.IT propose consiste en une sorte de simulation du travail du traducteur dans sa consultation et son interprétation des ressources documentaires dont il dispose : corpus, dictionnaires, bases de données, mémoires de traduction. Dans cette plateforme nous avons essayé de faire converger les avancées de trois disciplines relativement récentes dans le panorama linguistique international, à savoir la linguistique de corpus, la lexicographie computationnelle et la traductique. QU.IT est de fait une ressource électronique qui intègre à la fois 1) un corpus comparable monolingue, 2) un corpus parallèle bilingue, 3) une base de données lexicographiques et 4) une mémoire de traductions annotées. Par sa création, nous souhaitons éveiller un intérêt pour la création d’outils spécialement conçus pour faciliter le travail d’un traducteur qui ne peut se contenter des dictionnaires bilingues actuellement disponibles (cf. SIN-WAI, 2004). Dans cet article, nous montrerons aussi que « l’ordinateur, loin de restreindre le champ de pensée du traducteur, peut au contraire stimuler sa créativité et sa réflexion linguistique » (FONTENELLE 1993 : 28).

1. Un corpus comparable monolingue
Une ressource en ligne est différente d’un dictionnaire classique à plus d’un titre : « d’abord concernant la nature des entrées répertoriées. Ensuite, concernant leur organisation interne et, enfin, concernant le type d’informations linguistiques qu’il contient sur les mots de la langue » (GUIDÈRE 2010 : 143). Le premier avantage d’une base de données électronique est qu’il n’y a plus de limites d’espace. Les entrées peuvent contenir idéalement tous les faits linguistiques et encyclopédiques que le concepteur voudrait y voir figurer. Le sentiment de frustration que connait si bien le traducteur ne trouvant pas le mot recherché n’a plus raison d’être. À l’état actuel, on obtient dans QU.IT trois fois la quantité de québécismes répertoriés dans l’ensemble des dictionnaires bilingues français-italien sur le marché. Cette nomenclature, qui provient d’une partie de la nomenclature du Fichier Lexical du Trésor de la Langue Française au Québec, est destinée à s’élargir ultérieurement.3 Comme nous l’avons expliqué dans ZOTTI (2014a : 321-322) :
[…] la grande richesse et variété de cette nomenclature montre que les québécismes y sont traités en fonction des pratiques linguistiques des locuteurs québécois. En particulier, on remarque la présence de nombreux québécismes de registre familier et populaire (astheure, blonde, tanné, etc.), qui étaient presque complètement absents de la liste des bilingues. […] Un autre atout de QU.IT est de donner accès à un grand nombre de realia (atoca, baloné, épluchette de blé d’Inde, poutine, tire d’érable, tourtière) et de locutions idiomatiques du passé et du présent, absentes des autres répertoires.
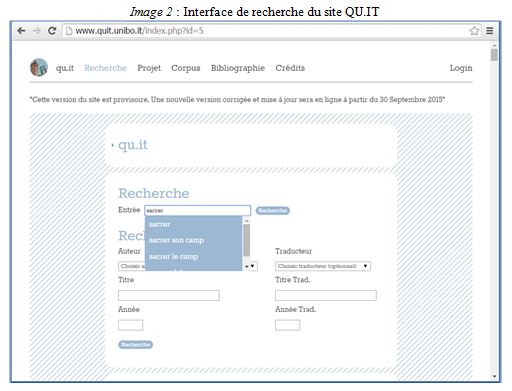
La localisation des expressions idiomatiques, proverbes et expressions composées de plusieurs mots est un des problèmes les plus fréquents que doit affronter le traducteur. Les dictionnaires ne sont pas toujours cohérents (sous quel composant faut-il rechercher l’expression ?), ce qui peut représenter une perte de temps importante pour le traducteur. Dans sa nomenclature (champ « Entrée » de la page Recherche, voir Image 2), QU.IT donne l’expression idiomatique en entier sous sa forme lemmatisée, avec ses éventuelles variables, ce qui se chiffre en gain de temps.
Le deuxième atout de la base QU.IT est qu’elle permet de trouver le québécisme recherché en discours. Jusqu’à la fin du XXe siècle, un grand nombre de traducteurs reprochaient aux dictionnaires de « passer sous silence tous les problèmes liés à la mise en discours » (HUMBLEY 2002 : 96). Les résultats de la recherche d’une entrée dans QU.IT sont des extraits d’ouvrages littéraires québécois (prose, poésie, théâtre et, depuis peu, aussi bandes dessinées) contenant le québécisme recherché.
Kilgariff (1997) a démontré que l’occurrence d’un mot en contexte, sous forme de citation ou de concordance, fournit une définition plus opérationnelle que le concept de « sens d’un mot » qui, selon lui, n’est pas viable. Pour lui, les sens / définitions des mots sont des abstractions de groupes d’emplois / usages des mots. En examinant un large nombre de concordances dans un corpus textuel, on est en mesure d’obtenir des informations plus amples que celles qui sont données par un dictionnaire sémasiologique traditionnel, qui se limite généralement à fournir des indications sur le sémantisme du mot et un compte-rendu abrégé, donc souvent incomplet, de ses usages.
QU.IT donne ainsi la possibilité d’avoir accès aux différents usages d’un québécisme donné à l’intérieur de son corpus littéraire monolingue. Dans l’exemple de face que l’on détaillera dans la suite de cet article (paragraphe 4), on verra que, en parcourant les différentes attestations du corpus français, l’utilisateur obtient des informations sur les différences d’usage du mot qui font partie d’un même sens. Le corpus donne ainsi des informations additionnelles que la consultation du seul dictionnaire de langue ne suffirait pas à illustrer.
2. Un corpus parallèle de traduction (bilingue et plurilingue)
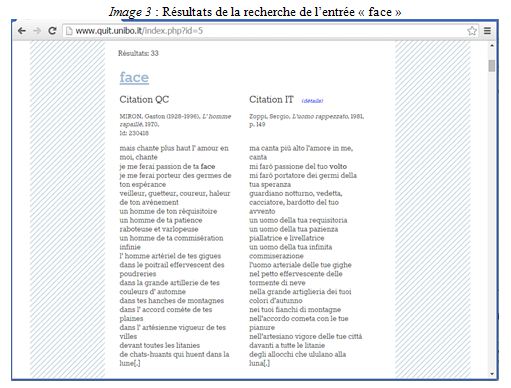
À notre connaissance, il n’existe pas aujourd’hui d’application multimédia, ni de ressources en ligne intégrées et spécifiquement dédiées à la lecture en langue étrangère de tous niveaux à l’usage des apprenants francophones qui proposent (i) une traduction contextualisée de tous les mots et expressions de ces textes, et (ii) des phrases extraites de très grands corpus multilingues alignés (également appelés bi-textes) pour illustrer ces traductions sous forme de concordances bilingues (DEVILLE et al. 2013 : 291). Même si ce n’est que pour une portion limitée du lexique français,4 QU.IT répond à ce manque en fonctionnant aussi en tant que corpus parallèle de traduction. Chaque citation littéraire est accompagnée de sa traduction italienne5 (voir Image 3), provenant de sa traduction publiée (cf. ZOTTI 2011 : 451).
Au contraire d’un dictionnaire bilingue sous format électronique qui est toujours consulté hors contexte, le choix de la traduction d’un mot étant laissé à l’initiative de l’utilisateur, QU.IT propose des traduisants intégrés dans des contextes réels. Le traducteur peut ainsi utiliser la base comme source d’inspiration pour obtenir des propositions de traduction non pas d’un mot pris singulièrement, mais du mot dans un contexte donné et en tenant compte de plusieurs paramètres tels que le sens, bien-sûr, mais aussi le registre, le ton, la connotation, le genre textuel, etc. S’il cherche par exemple des propositions pour traduire un mot de registre familier, il pourra choisir de consulter dans le corpus parallèle des ouvrages littéraires plus représentatifs de ce registre, en sélectionnant dans la « Recherche avancée » l’auteur ou l’œuvre qui l’intéressent6 et obtenir ainsi des options qu’il devra valider pour sa propre traduction.
Comme l’a affirmé la traductologue BAKER (1998 : 482), « certains traducteurs et traductologues pourront trouver que cette approche qui semble mettre l’accent sur des traits tels que la normalisation et la structure récurrente en général est inquiétante, car, à première vue, elle semble ne pas tenir compte du comportement individuel ou créatif qui caractérise pourtant les textes traduits, particulièrement les textes littéraires ». Au contraire, lorsqu’on a la possibilité de disposer d’un très grand nombre de textes en format électronique et qu’on peut créer du bout du doigt toutes sortes de statistiques et d’études de fréquence des événements linguistiques qui se répètent dans les corpus, il est plus simple de mener des études qui vont plus en profondeur. Tout cela se fait de toute façon dans le respect de la créativité que le traducteur met en jeu. En effet, comme BAKER (1998 : 483) le soutient : « une des raisons qui nous poussent à étudier la structuration de toutes sortes de productions textuelles, y compris la traduction, est que les structures constituent la toile de fond qui donnera forme à la créativité ».
3. Une base de données lexicographiques
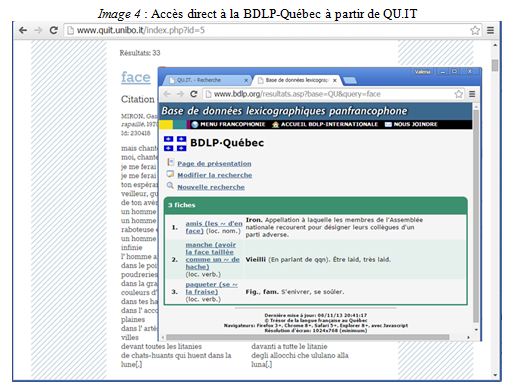
QU.IT donne aussi au traducteur la possibilité d’accéder à une description lexicographique approfondie de québécismes qu’il a déjà observés à l’intérieur du corpus. Un lien externe à la base de données lexicographiques panfrancophone BDLP-Québec (et prochainement au dictionnaire électronique USITO) s’active en cliquant sur le mot-entrée en bleu au-dessus de chaque citation (voir Image 4).
En cliquant sur le symbole du petit livre à côté de chaque citation québécoise (voir plus loin Tableau A), on peut ouvrir une fiche interne à la base QU.IT, qui propose un classement fondé sur le signe linguistique du québécisme (POIRIER, 1995)7 et son analyse intralinguistique (effectuée par un rédacteur de QU.IT, étudiant de deuxième cycle universitaire sous notre supervision). Cette fiche rassemble des informations linguistiques et, si nécessaire, encyclopédiques, sur le mot en question tirées d’autres dictionnaires monolingues français (PR et TLF) et québécois (DQA, etc.) et triées par le rédacteur de QU.IT en fonction du sens du mot dans un contexte donné.
L’expérience montre que les traducteurs se servent davantage d’un dictionnaire monolingue qu’ils trouvent « plus précis et plus complet pour la compréhension des unités à traduire » (GUIDÈRE 2010 : 141). Cependant, nous avons observé que « les traducteurs italiens de la littérature québécoise ignorent souvent l’existence de dictionnaires de langue ou différentiels conçus au Québec qui pourraient pourtant résoudre leurs problèmes de compréhension d’unités lexicales ou phraséologiques du français québécois » (ZOTTI 2014 : 315). De la sorte, en consultant QU.IT, le traducteur ne doit pas effectuer un grand nombre de recherches documentaires externes et peut rassembler immédiatement des informations sur les particularismes de la langue et de la culture québécoises qu’il pourrait ne pas connaître.
QU.IT peut être ainsi apparenté à un système de Traduction Assistée par Ordinateur (T.A.O.), un outil informatique mis à la disposition du traducteur pour accélérer et faciliter sa tâche. Si le système ne remplit pas la fonction d’un traducteur, il lui permet, en le faisant « dialoguer en accès direct avec un dictionnaire et d’autres aides à la recherche » (CARESTIA-GRENFIELD et SERAIN 1979 : 80) de produire des traductions de haute qualité avec une réduction importante de temps et d’efforts par rapport aux méthodes traditionnelles des traductions humaines.
4. Une mémoire de traduction et un outil d’analyse contrastive
QU.IT donne accès à un autre type de fiche : une fiche d’analyse contrastive français-italien. On y vérifie si les traduisants attestés dans le corpus parallèle sont acceptables et, si nécessaire, des propositions de correction sont données par les rédacteurs, qui ont été préalablement sensibilisés et formés aux problèmes de traduction du français québécois, toujours en fonction du contexte de lecture. Des commentaires liés à ces propositions sont également proposés. Le but de ces fiches est de guider le traducteur vers le choix de la traduction la plus appropriée.
Guidère (2010 : 140) a remarqué que « les dictionnaires bilingues ne sont pas proposés pour servir d’aide immédiatement exploitable par le traducteur, mais pour servir à la compréhension du sens général des entrées choisies ». Pour comprendre dans quelle mesure QU.IT est un outil informatique qui pourrait être utilisé comme un dictionnaire de traduction, il convient de préciser la distinction de principe entre le dictionnaire bilingue et le dictionnaire de traduction qui vise à répondre aux besoins spécifiques du traducteur professionnel.
Le premier donne traditionnellement des correspondances hors contexte entre des mots et des expressions dans deux langues différentes, tandis que le second est censé fournir des équivalences contextuelles entre des usages discursifs spécifiques et actualisés. La différence est essentielle : l’un encode la langue, l’autre décode le discours. Contrairement au dictionnaire bilingue qui donne la traduction correspondant au sens d’un mot ou d’une expression, le dictionnaire de traduction fournit des équivalences d’usage pour un mot ou une expression dans différents contextes verbaux. Il est, de ce point de vue, une sorte de « mémoire de traduction » qui contiendrait les traductions les plus stables et les plus usitées pour certains types de textes ou genres de discours. Ainsi, le dictionnaire de traduction doit être conçu d’abord comme une base de données d’équivalences lexicographiques contextuelles, variées et authentiques. Autrement dit, il doit comporter le maximum de phrases traduites et validées pour le maximum de collocations et d’expressions concernant un vocable. C’est là un aspect qu’il partage avec le dictionnaire de décodage, mais ce qui intéresse le traducteur professionnel lorsqu’il consulte le dictionnaire bilingue, ce n’est pas tant la compréhension du sens des unités linguistiques que les différentes manières de les traduire. (GUIDÈRE 2010 : 141)
En fonctionnant à la fois comme un corpus d’attestations et comme une mémoire de traduction, QU.IT permet de donner des indications concrètes quant aux différentes stratégies possibles de traduction pour un type de lexie donnée. L’intégration du classement des québécismes de POIRIER (1995) que nous avons évoqué plus haut sert de fait à établir des statistiques des stratégies de traduction utilisées en fonction de la nature du québécisme et de son sens, du contexte et du genre textuel dans lequel il apparaît.8 À ce propos, à l’état actuel nous avons intégré dans la fiche d’analyse contrastive des menus déroulants qui permettent au rédacteur de choisir parmi les différentes stratégies de traduction telles que décrites par VINAY et DARBELNET (1966) et par DELISLE (1980), et, pour la traduction des expressions idiomatiques, par BAKER (1992).
Pour illustrer son fonctionnement, nous verrons dans les prochains paragraphes des exemples de consultation pratique de QU.IT. Nous avons choisi le mot face, qui présente des difficultés de traduction liées justement à l’usage différent qui en est fait au Québec par rapport au standard européen.
5. Exemple de consultation de QU.IT : le québécisme de statut « face »
5.1. Le corpus monolingue et la base lexicographique
Nous rapportons ci-après les résultats de la recherche du mot face dans le corpus parallèle bilingue français-italien. Trente-trois citations de la littérature québécoise contenant ce mot figurent parmi les résultats. L’information bibliographique abrégée est donnée au-dessus de chaque citation (voir Tableau A), l’information complète figurant dans les sections Corpus et Bibliographie du site QU.IT. Par souci de brièveté nous n’avons pas rapporté toutes les citations ici.



Le mot face existe tant en français de référence (FrR) qu’en français québécois (FQ) avec le sens de « Partie antérieure de la tête de l'homme » (PR, TLF), mais en français québécois, il n’occupe pas la même situation de fait qu’en FrR. La différence réside dans la fréquence relative d'emploi (FQ courant, FrR rare dans ce sens). Il est pour cela classé parmi les québécismes de statut9 (POIRIER 1995 : 36). En FrR le mot face dans son acception physique est de plus désuet aujourd'hui : on lui préfère les synonymes visage, tête, figure. Son emploi est encore courant dans des expressions métaphoriques où face a l'acception de « dignité » (ex. perdre la face) ou dans des expressions figées qui se réfèrent aux qualités morales qui s’expriment par son apparence (TLF : « face de cire, de pleine lune, etc. »).
Les différents usages que l’on fait de ce mot dans les contextes attestés par le corpus monolingue (colonne de gauche, voir Tableau 1) se réfèrent tant à la partie du corps (dans Hébert 1, 3, 4, 5) qu’à l’expression du visage (dans Hébert 2 et Miron 6). La lecture des différentes citations tirées de la littérature québécoise permet donc au traducteur de prendre conscience du fait que l’emploi du mot face est courant au Québec aussi dans son acception physique. Il obtient ainsi des informations plus fines sur l’usage réel du mot en contexte qu’il ne trouverait pas dans un dictionnaire de langue.
Dans la base, en cliquant sur l’icône livre à côté de chaque Citation QC (voir Tableau A), l’utilisateur a accès à une fiche dans une fenêtre intruse (voir Figure X) qui présente le classement du québécisme selon la classification de POIRIER (1995), sur l’axe différentiel et sur l’axe historique (cf. Note 7) et l’analyse intralinguistique du québécisme. Il peut ainsi vérifier directement le sens et la connotation du mot en question dans les principales ressources lexicographiques françaises et québécoises déjà citées. Des remarques complètent cette analyse avec des précisions supplémentaires utiles au traducteur.

De cette manière, l’utilisateur de QU.IT accède rapidement à des sources fiables, qu’il pourrait ne pas connaître et qui ont été sélectionnées par le concepteur de la base et consultées à bon escient par des rédacteurs convenablement formés sur le français québécois. Cette base sur support informatique simplifie ainsi la vie du traducteur en lui permettant un gain de temps pour ce qui concerne la recherche lexicale et documentaire.
5.2. Le corpus parallèle et la mémoire de traductions
L’observation du corpus parallèle (colonne de droite, Tableau 1) donne accès aux différentes traductions proposées pour ce mot. Les traduisants viso et volto sont privilégiés par la traductrice Vilma Porro pour les deux sens rencontrés (dans Hébert 1-2-3-4). Par contre, la traductrice Alessia Pasqualini (dans Hébert 5) choisit le traduisant faccia dans un contexte où les traits physiques et l’apparence du visage sont décrits (« face faite de poils hérissés et de taches de boue »). En italien, en effet, faccia et viso sont le plus souvent interchangeables : on les emploie indistinctement pour indiquer à la fois les conditions physiques et morales d’un individu, ainsi que sa physionomie. Viso est, d’après le Vocabolario Treccani (www.treccani.it/vocabolario), un synonyme plus recherché et a un emploi plus limité que faccia, ils ne peuvent se substituer l’un à l’autre dans plusieurs expressions : viso est fréquent par exemple dans des expressions admiratives qui se réfèrent surtout aux femmes (ex. ha un bel viso, elle a un beau visage). Faccia et viso sont donc similaires d’un point de vue purement sémantique, mais pas pour ce qui concerne leur usage et leur fréquence.
Le choix du traduisant faccia (dans Hébert 5) nous semble adéquat dans ce contexte spécifique, parce qu’il est employé pour se référer à un méchant, Adélard. La connotation péjorative passe ainsi aussi par le choix de ce traduisant, que nous supposons réfléchi de la part de la traductrice. Elle aurait pu aller plus loin en proposant d’autres mots péjoratifs, comme muso ou grugno (gueule) pour mettre davantage en relief les caractéristiques négatives du personnage.
Dans la base QU.IT, en cliquant sur le lien hypertextuel (détails) à côté de chaque Citation IT (voir Tableau 1), l’utilisateur a accès à un autre type de fiche qui présente cette fois une analyse contrastive français-italien et une évaluation du traduisant proposé à l’intérieur de chacune des citations traduites. Ainsi, pour la Citation IT Hébert Id : 5, la fenêtre qui s’ouvre donne les informations suivantes (voir Figure Y).

Pour ce qui concerne le traduisant volto, présent dans la traduction du célèbre recueil L’homme rapaillé de Gaston Miron traduit par Sergio Zoppi, il s’agit d’un synonyme littéraire plus recherché que viso et faccia. Le choix de ce traduisant semble tout à fait pertinent dans un texte poétique. La fiche qui s’ouvre en cliquant sur (détails) à côté de la Citation IT dans Miron Id : 6 présente l’analyse contrastive de ce mot avec la justification de l’acceptation de ce traduisant.
Lorsque le traduisant proposé par le traducteur officiel n’est pas considéré comme adéquat par l’analyste de la base QU.IT, il sera indiqué comme « non acceptable » (dans la première ligne de la fiche d’analyse contrastive, signalé par une case cochée) et un traduisant plus pertinent pour le contexte donné sera proposé. Pour illustrer ce cas de figure, nous donnerons un dernier exemple : un mot de registre familier, niaiseux.
6. Exemple de consultation de QU.IT : le québécisme léxématique « niaiseux »
Nous avons choisi un mot qui se situe à la fois sur l’axe diastratique et diaphasique : il s’agit d’un mot du joual, un sociolecte québécois issu de la culture populaire urbaine de la région de Montréal et qui est resté dans l’usage familier contemporain. Il figure souvent dans les pièces théâtrales de M. Tremblay, principal représentant de la littérature joualisante. Faute d’espace, nous ne rapportons pas ici les citations du corpus et les fiches détaillées d’analyse intralinguistique et contrastive de ce mot. Le premier problème qui se pose au traducteur est celui de la compréhension de son sens. C’est en effet un québécisme lexématique, un lexème original qui n’existe pas en FrR. Niaiseux est un adjectif qui peut avoir un sens légèrement différent selon le contexte lorsqu’il se réfère à des personnes : « Qui est dénué d'intelligence, de jugement. → bête, imbécile, niais, sot, stupide; fam. sans-dessein », ou bien « Peu débrouillard, empoté, maladroit » (USITO).
Dans le corpus QU.IT, la plupart des citations québécoises attestent le premier sens correspondant à « sot, stupide ». Les traductions italiennes présentent comme traduisant des équivalents sémantiques (stupido, stolto, cretina, deficiente), sauf dans un cas (Tremblay Id : 1, voir Tableau B) où, dans deux contextes où sont donnés des éléments supplémentaires sur les caractéristiques du personnage (« bon-rien »), la traductrice Francesca Moccagatta a choisi d’utiliser l’expression italienne morto di fame (« crève-la-faim ») qui, bien qu’elle ne corresponde pas exactement au sens de niaiseux10, a une connotation péjorative et injurieuse qui rend bien le blâme exprimé par Germaine Lauzon et active une compensation par rapport à d’autres parties du texte où ces connotations sont perdues.

Ce cas est ainsi un exemple de ce que l’on pourrait considérer comme une traduction qui « trahit » le texte de départ sur le plan sémantique, mais qui peut être jugée comme tout à fait pertinente et efficace lorsqu’elle est justifiée par un souci plus large de fidélité au ton général du texte. Dans un dictionnaire bilingue traditionnel, on ne trouverait jamais un traduisant de ce type, qui n’appartient pas au même champ sémantique mais plutôt au même champ analogique que le mot povertà (pauvreté). Par contre, le dictionnaire onomasiologique permet au traducteur d’opérer des choix lorsqu’il est mis en présence de mots sémantiquement liés (cf. FONTENELLE 1993 : 30). Or, on sait que les traducteurs professionnels ont souvent recours aux dictionnaires onomasiologiques (ou analogiques)11 qui répondent à des lacunes verbales pour trouver un traduisant idiomatique, en particulier pour la stratégie de la modulation (cf. ZOTTI 2014b : 159). Dans le cas de la traduction morto di fame, la stratégie adoptée par la traductrice Moccagatta est en effet une modulation.
En dernier essor, la base QU.IT peut être consultée comme un dictionnaire bilingue de traduction « à rebours » qui a aussi les caractéristiques d’un dictionnaire onomasiologique : en proposant une vaste gamme de traduisants à l’intérieur du corpus parallèle, QU.IT permet au traducteur d’être aidé dans la tâche difficile de traduire non pas des mots mais des idées. Les modalités d’enregistrement, d’organisation et de recherche des données permises par QU.IT peuvent donc fournir au traducteur la source d’inspiration qui lui manque en enrichissant son vocabulaire et en multipliant la gamme de traduisants qu’il est susceptible de choisir. « C’est ce que Snell-Hornby (1991) appelle en anglais du decision-making material : au traducteur de laisser ensuite libre cours à sa créativité » (FONTENELLE 1993 : 34).
Conclusion
QU.IT est une plateforme qui englobe plusieurs ressources différentes : corpus monolingue, corpus parallèle, fiches lexicographiques monolingues, fiches d’analyse contrastive. L’approche que nous avons adoptée dans la création des ressources de cet outil s’inscrit dans le Traitement Interactif de la Langue (TIL) qui ouvre des pistes de recherche prometteuses, explorées par Zock et Lapalme (2010).
En tant que corpus, QU.IT donne accès à des contextes et à des options de traduction qui ne relèvent pas seulement de critères sémantiques (comme le fait un dictionnaire bilingue traditionnel basé sur l’équivalence mot-à-mot) mais aussi de différentes stratégies prenant en compte aussi des critères syntaxiques, comme la reformulation, la transposition, et des critères analogiques, comme la modulation.
En tant que base lexicographique, QU.IT est une source de connaissances où le lexical (dictionnaires de langue) se mêle à l’encyclopédique. Son support informatisé permet de s’affranchir des contraintes dues à l’ordre alphabétique, en particulier pour les expressions figées, et d’accélérer le travail documentaire du traducteur.
Enfin, comme mémoire de traduction, QU.IT propose des stratégies de traduction possibles et les préférences de certains traducteurs. Le traducteur littéraire qui n’est pas spécialiste du français québécois est aidé par la lecture des fiches d’analyse contrastive, rédigées par les rédacteurs de la base formés sur la traduction et sur la variation topolectale du français.
Toutes ces composantes, loin d’abrutir le traducteur sous une masse informe de données, pourraient l’aider à structurer sa pensée et le guider sur la voie de la créativité qui est le propre de la traduction littéraire.
Bibliographie
M. BAKER, « Idioms and fixed expressions », in M. BAKER (éd.), In other words, London et New York : Routledge, 1992, p. 67-91.
M. BAKER, « Réexplorer la langue de la traduction : une approche par corpus », Meta : journal des traducteurs, vol. 43, n°4, 1998, p. 480-485.
C. CARESTIA-GRENFIELD et D. SERAIN, La traduction assistée par ordinateur, des banques de terminologie aux systèmes interactifs de traduction, Paris : AFTERM, août 1979.
C. SIN-WAI (éd.), Translation and Bilingual Dictionaries, Lexicographica. Series Maior 119, Tubingen : Niemeyer, 2004.
G. DEVILLE, L. DUMORTIER, J.-R. MEURISSE et M. MICELI, « Ressources lexicales pour l'aide à l'apprentissage des langues », in N. GALA et M. ZOCK (dir.), Ressources lexicales. Contenu, construction, utilisation, évaluation, John Amsterdam/Philadelphia : Benjamins Publishing Company, 2013, p. 291-312.
J. DELISLE, L’analyse du discours comme méthode de traduction, Ottawa : Editions de l’Université d’Ottawa, 1980.
Th. FONTENELLE (1993), « Le traducteur et le dictionnaire bilingue : l’apport de la lexicographique computationnelle », in Le traducteur et ses instruments, Palimpsestes, n. 8, Paris : Presses de la Sorbonne Nouvelle, p. 27-40.
M. GUIDÈRE, Introduction à la traductologie. Penser la traduction : hier, aujourd'hui, demain, Bruxelles : De Boeck, 2010, 2e éd.
J. HUMBLEY, « Nouveaux dictionnaires, nouveaux rapports avec les utilisateurs », Méta : journal des traducteurs, vol. 47, n° 1, 2002, p. 95-104.
A. KILGARIFF, « "I don't believe in word senses" », Computers and the Humanities, n. 31, 1997, p. 91-113.
Y. LEBTAHI, « Traducteurs dans la société de l’information. Evolutions et interdépendances », Méta : journal des traducteurs, vol. 49, n° 2, juin 2004, p. 221-235.
C. POIRIER, « Les variantes topolectales du lexique français : proposition de classement à partir d’exemples québécois », in M. FRANCARD ET D. LATIN (éds.), Le régionalisme lexical, Louvain-la-Neuve : Duculot, 1995, p. 13-56.
J. PRUVOST, Les dictionnaires français, outils d’une langue et d’une culture, Paris : Ophrys, 2006.
M. SNELL-HORNBY, « The translator’s dictionary : an academic dream », Inaugural Conference of the European Society for the Study of English (Norwich, 4-8 September 1991).
B. VAUQUOIS, « L’informatique au service de la traduction », Méta : journal des traducteurs, vol. 26, n. 1, 1981, p. 9-17.
J-P. VINAY et J. DARBELNET, Stylistique comparée de l’anglais et du français, Paris : Didier, 1966.
M. ZOCK et G. LAPALME, « Du TAL au TIL », in Actes de TALN 2010, Montréal (19-23 juillet 2010).
V. ZOTTI, « La transposition des mots et des mondes : pour la constitution d’une base parallèle des traductions italiennes de la littérature québécoise», Etudes de Linguistique Appliquée, vol. 164, n° 4, 2011, Paris : Didier Erudition, p. 447-463.
V. ZOTTI, « Un nouveau scenario pour la station de travail du traducteur : la base de données lexicales QU.IT. Québec-Italie »,in Farina, A., Zotti, V. (dir.), La variation lexicale des français. Dictionnaires, bases de données, corpus.Hommage à Claude Poirier, Paris : Honoré Champion, 2014a, p. 311-331.
V. ZOTTI, « Les renvois analogiques du Petit Robert : un système sémiotique complexe », in HEINZ, M. (éd.), Les sémiotiques du dictionnaire. Actes des 5e Journées Allemandes des Dictionnaires (Klingenberg am Main, 6-8 juillet 2012), Berlin : Frank & Timme, 2014b, pp. 133-161.
V. ZOTTI, « QU.IT. une ressource électronique mise à disposition des traducteurs italiens pour ‘comprendre’ la dia-variation du français (québécois) », in La dia-variation en français actuel. Etudes sur corpus, approches croisées et ouvrages de référence, Berne : Peter Lang, 2015, collection "Sciences pour la communication", p. 319-346.
Bases de données et dictionnaires
BDLP-Québec = TLFQ, Base de Données Lexicographiques Panfrancophone-Québec
DQA = Boulanger, J. C. et Rey, A., 1992, Dictionnaire Québécois d’Aujourd`hui, Montréal-Paris : Le Robert.
Fichier Lexical =Trésor de la langue française au Québec, Fichier Lexical, < http://www.tlfq.ulaval.ca/fichier/>.
PR = Le nouveau Petit Robert, dictionnaire alphabétique et analogique de la langue française, Rey-Debove, J. et Rey, A. (dir.), Paris, Le Robert [version en ligne 2011].
QU.IT. = Zotti, V. (dir.), 2013, QU.IT. Base parallèle de la littérature québécoise traduite en italien, Università di Bologna, Centro di Risorse per la Ricerca Multimediale (CRR-MM),
TLF = Trésor de la langue française. Dictionnaire de la langue du xixe et xxe siècle (1789-1960), 1971-1994, édité par P. Imbs (vol. 1-10), Paris, CNRS, et par B. Quemada (vol. 11-16), Paris : Gallimard ; version informatisée < http://atilf.atilf.fr/>.
Treccani = Istituto dell’Enciclopedia Italiana, Vocabolario della lingua italiana Treccani, 1997, 2e éd.,
USITO = Cajolet-Laganière, H. Martel, P. (dir.), Dictionnaire du Français en Usage au Québec (accès limité),
Notes
↑ 1 Mis à part les nombreux projet d’Humanités numériques qui consistent plutôt dans la conversion d’ouvrages littéraires existants du format papier au format électronique, ce qui n’a aucun rapport avec le sujet de cette étude qui porte sur la création d’outils spécifiques de support au travail du traducteur littéraire.
↑ 2 Des mots qui ont la même forme en français de référence et en français québécois mais une signification différente.
↑ 3 Pour les critères de constitution du corpus, cf. ZOTTI (2011 : 449-451).
↑ 4 Ce projet, limité à la description des variantes topolectales du français au Québec, se veut une expérimentation d’une méthode qui pourrait être appliquée à des projets de plus grande envergure prenant en compte toute la langue française.
↑ 5 Une nouvelle version du corpus parallèle sera plurilingue et contiendra aussi les traductions anglaises et espagnoles.
↑ 6 Dans le cas du français québécois, à titre d’exemple il pourra consulter les traductions des pièces de Michel Tremblay pour le français populaire ou les contes de Nadine Bismuth pour le registre familier.
↑ 7 La grille que POIRIER (1995) a élaborée permet de restituer aussi bien la nature des différences avec le FrR (axe différentiel) que l’origine des emplois québécois (axe historique). Selon l’axe différentiel, qui explique en quoi la variante du français québécois (FQ) prise en compte est originale par rapport au FrR, les québécismes sont divisés en : lexématiques, sémantiques, grammaticaux, phraséologiques, et de statut. Selon l’axe historique, qui rend compte de la source des emplois, ils sont divisés en archaïsmes, dialectalismes, amérindianismes, anglicismes et innovations.
↑ 8 Par exemple, quelles sont les différentes manières de traduire des québécismes sémantiques, ou des realia, ou des amérindianismes ? Le traducteur du corpus parallèle met-il en œuvre des stratégies particulières ? Utilise-t-il plutôt une glose explicative ou une adaptation ou un emprunt ? Son choix peut-il être considéré comme convenable ?
↑ 9 Le mot, qui existe en FrR dans la même forme et avec le même sens, présente des spécificités en FQ concernant le domaine d’emploi (arachide usuel, FrR langue commerciale), la fréquence relative (miroir courant, plutôt glace FrR), la connotation (se déshabiller neutre en FQ pour « enlever ses vêtements d’extérieur ») (POIRIER 1995 : 36).
↑ 10 Dans une optique interlinguistique, morto di fame a en commun avec niaseux le trait sémantique de « persona incapace » (DO), « bon-à-rien ».
↑ 11 « Le classement analogique est celui qui rassemble des mots ayant au moins un trait de signification en commun » (PRUVOST 2006 : 112).